
Today I happened to visit the wiki page of Pierre-Simon Laplace. And saw the sun rise problem. I only have a quite vague memory of it so I decided to read through. The problem is quite simple: you have seen the sun rise for the past 
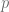
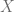
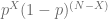

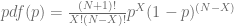
Using law of total probability, which means 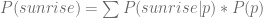
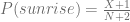
That means, for someone like me, 28.5 years (7553 days) of seeing or knowing (yes, it rains) the sun rises, the probability of sun not rising tomorrow is 0.014%. Which is actually not as small as I thought….
Now, here are the two questions I want to address.
- Are we using uniform prior here? Or we are using beta distribution as prior? Different sources are different.
- Why not
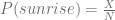
The first one confused me for a while today. From most of the places I read about this problem, people mention they assume a uniform prior for
Of course not. You can also use beta distribution, and actually they are equivalent. Using uniform prior from the beginning and compute the posterior after N days is equivalent to using a beta distribution (start with 

The second one is also quite interesting. The explanation on wiki is like you can get that result if you are “total ignorant of
No doubt,
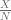
Why? Because it is not computing the mean of posterior, rather it is computing the mode (or, maximize a posteriori, MAP, the maxima of the posterior distribution).When the distribution is skewed, the expectation and mode will be different. (Not the case for ridge regression, which is actually computed using MAP)
There are a lot of articles talking about MAP, pros and cons, attacks and defense. But all in all, I think it is much convenient to use for both value and variance estimation 😀
